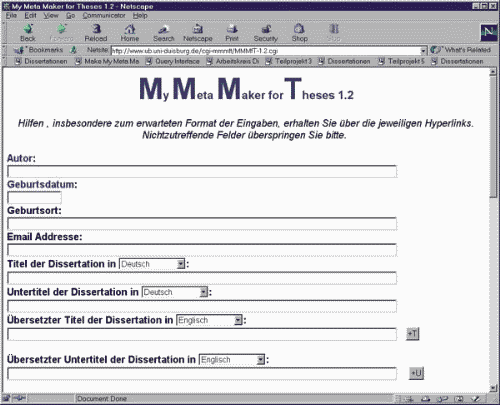
 Abbildung 1: Screenshot des MMMfT
Abbildung 1: Screenshot des MMMfT
A. Überblick über das Projekt
Von Hans-Ulrich Kamke; Humboldt-Universität zu Berlin
1. Einleitung
2. Vorgeschichte
3. Das Projekt Dissertationen online im Rahmen des DFG-Projektes...
4. Das DFG-Projekt
4.1 Aufgaben und Ziele
4.2 Die Teilprojekte
4.3 Ergebnisse und Weiterarbeit
B. Teilprojekt Beratung und Unterstützung
von Steffi Dippold und Stefan Groß; Humboldt-Universität zu Berlin
1. Informationsvermittlung, nicht Informationsüberlastung
2. Schulung der Doktoranden
3. Dissinfo - ein Informationsangebot im Internet
4. Explosion des Wissens
5. Weg aus der Einbahnstrasse
6. Kontakt nach außen
von Thorsten Bahne; Gerhard-Mercator-Universität Duisburg
D. Teilprojekt Retrieval und rechtliche Aspekte
1. Hintergrundinformationen zu Metadaten
2. Metadaten in Dissonline
2.1 Datensatzentwicklung
2.2 Tools
2.3 Installation
2.4 Nutzung
3. Suche mit Metadaten
von Kerstin Zimmermann; Carl-von-Ossietzky-Universität Oldenburg
1. Weltweites Retrieval nach und in Dissertationen
1.1 Harvest: Funktionsweise
1.2 Aufbau eines Harvest-Netzwerkes
1.3 Kooperationen mit anderen Systemen
2. Rechtliche Aspekte bei elektronischen Dissertationen
2.1 Promotionsverfahren
2.2 Online Publikation
2.3 Nationale Datenbanken
von Matthias Schulz und Susanne Dobratz; Humboldt-Universität zu Berlin
1. Dokumentformate
1.1 Was ist ein Dokument?
1.2 Dokumentformate für die Archivierung und das Retrieval
1.3 Dokumentformate für die Präsentation und den Druck
2. Die DiML-Dokumenttypdefinition
2.1 Beschreibung der DiML-DTD
2.2 Vergleich / Kooperation mit anderen Dissertations-DTD's
3. Wissensmanagement mit SGML/XML-Dokumenten
F. Teilprojekt Multimedia
von N.N.; Computer Chemie Centrum Universität Erlangen
1. Multimediadaten in der Chemie
1.1 Voraussetzungen für die Nutzung von Strukturdaten (Aufbereitung der Rohdaten)
1.2 Suche in Chemischen Strukturen
2. Multimediadaten in anderen Wissenschaften
2.1 Datenformate
2.2 Zur Akzeptanz und Nutzung von Multimediadaten in den Wissenschaften
von Hans Becker; SUB Göttingen
1. Bibliothekarische Aspekte bei der Publikation elektronischer Dissertationen
2. Integration in den Workflow der Universitätsbibliotheken
3. Zusammenarbeit mit Der Deutschen Bibliothek
H. Dissertationen Online: Ergebnisse und Ausblick
von Peter Diepold; Humboldt-Universität zu Berlin
1. Ergebnisse der 2 Projektjahre
2. Dissertationen Online im internationalen Kontext
3. Wie geht es weiter mit Dissertationen Online?
II. Teilbericht 2
C. Teilprojekt Metadaten
von Thorsten Bahne Im zweiten Teil des Fortsetzungsartikels über das DFG-Projekt "Dissertationen Online" (http://www.dissonline.org) werden insbesondere die Themengebiete Metadaten und Retrieval behandelt. Im Teilprojekt Metadaten wurde gemeinsam mit der Deutschen Bibliothek ein dissertationsspezifischer Dublin-Core-Metadatensatz (http://www.ub.uni-duisburg.de/dissonline/metatags.pdf) entwickelt, der sich inzwischen bundesweit durchgesetzt hat und auch auf internationaler Ebene innerhalb der weltweit operierenden Initiative NDLTD (Networked Digital Library of Theses and Dissertations: http://www.ndltd.org), in der das deutsche Projekt auch Mitglied ist, diskutiert wurde. Metadaten ermöglichen es, z.B. über ein Netzwerk von Harvest-Brokern und Gatherern nicht nur die Volltexte zu indexieren, sondern auch speziell die Metadatenelemente, wie nach z.B. Gutachtern, Universitäten oder Schlagwörtern zu durchsuchen. 1. Hintergrundinformationen zu Metadaten
Bedingt durch die enorme Ausbreitung und Vertiefung des World Wide Web (WWW) und der damit verbundenen Fülle von Informationen wurde es notwendig, eine neue Ebene in der Beschreibung von elektronischen Dokumenten einzuführen. Die hieraus abstrahierten "Daten über Daten", also die Metadaten, bilden ein entsprechendes Instrumentarium, das es zu konfigurieren galt. Jeder Internet-User kennt das Problem, dass eine Suche mit den herkömmlichen Suchmaschinen zum Teil nicht die gewünschten Ergebnisse erzielt1. Ein effizientes Erschließen von Informationen im WWW kann aber nur dann als realistisch erscheinen, wenn eine hinreichende Normierung der neuen Datenebene erreicht worden ist, d.h. man benötigt Übereinkünfte über die Kennzeichnung der einzelnen Daten, damit z.B. der Titel auch eindeutig als Titel zu erkennen ist.
Unterschiedliche Experten, von Bibliothekaren über Wissenschaftler bis hin zu Spezialisten für Landkarten und digitale Texte, sind auf mehreren Fachtagungen in Dublin (Ohio), Warwick (England), Cambridge (Massachusetts) und Canberra (Australien) zusammengekommen, um sich mit dieser weitreichenden Problematik auseinander zu setzen.
Ziel dieser Tagungen war es, ein gemeinsames Modell für die allgemeine Erschließung von "Daten" zu erstellen. Dabei waren die Flexibilität des Datensatzes, d.h. seine Anwendbarkeit auf verschiedene Quellen, und die Einfachheit der Daten, d.h. man sollte nicht von Unmengen von Spezifikationen erschlagen werden, wichtige Punkte. Hieraus resultierte die grundlegende Vereinbarung, Quellen durch das sogenannte Dublin Core Element Set zu erschließen, das aus fünfzehn Kernelementen besteht2.
Um den Anforderungen der verschiedensten Nutzer und Dokumenttypen Rechnung tragen zu können, kann diese beschränkte Anzahl von Kategorien durch Hinzunahme von Subklassifikationen, Qualifiern3 und Schemes erweitert werden. Somit kann eine notwendige Spezifikation der Datenbeschreibung vorgenommen werden. Insgesamt entsteht ein flexibler Rahmendatensatz, der an die spezifischen Bedürfnisse angepaßt werden kann.
Die elektronische Veröffentlichung von wissenschaftlichen Hochschulschriften beschäftigt schon eine gewissen Zeit die Verantwortlichen in Bibliotheken und Wissenschaften, da die Entwicklungen im technischen Bereich diese neue Möglichkeit offerieren. Jedoch ist die Frage nach dem Workflow und dem allgemeinen Umfeld von digitalen Dokumenten noch ungeklärt. Aus diesem Grund haben sich in der Vergangenheit schon einige Projekte konstituiert, die sich mit den verschiedenen Typen von Online-Publikationen, wie z.B. Preprints oder Zeitschriften, beschäftigen. Wie auch in anderen Bereichen sollte auch hier im Bereich der Dissertationen versucht werden die vorhandenen Ergebnisse aufzugreifen und in eine allgemein akzeptierte Form zu überführen. Erst dieses Vorgehen kann eine weitverbreitete Zustimmung ermöglichen.
Vorgängerprojekte, die zum Teil recht erfolgreich waren, schufen eine Grundlage, auf der wir unsere Arbeiten basieren und auf deren Ergebnisse wir zurückgreifen konnten, um sie auf die Belange einer deutschen Dissertation zuzuschneiden. Aber welches sind diese speziellen Anforderungen?
Dissertationen kommt unter den Publikationen ein besonderer Stellenwert zu. Sie müssen verschiedenste Anforderungen verschiedener Bereiche erfüllen.
Eine Dissertation ist in der Regel eine aktuelle fachwissenschaftliche Publikation und auch das wohl wichtigste Dokument in einem individuellen Qualifizierungsprozess eines jungen Wissenschaftlers. Daher müssen die zu konzipierende Metadaten, d.h. zur Recherche notwendige Strukturinformationen über die entsprechenden Arbeiten, diesem Anspruch konsistent genügen. Somit ist es von Bedeutung gewesen, den fachwissenschaftlichen Belangen Rechnung zu tragen, d.h. es müssen Informationen über die fachliche Einordnung der Dissertation, sei es über Stichworte, über Klassifikationsschemata oder über Fachthesauri verfügbar gemacht werden.
Die bundesdeutschen Dissertationen unterliegen der gesetzlichen Veröffentlichungspflicht und sind ganz neutral betrachtet Publikationen, die von Bibliothekaren katalogisiert werden müssen. Daher kommt man nicht umhin, auch die Ansprüche der Bibliotheken im Metadatensatz zu berücksichtigen.
Neben diesen Aspekten sollte man aber den eigentlichen Hintergrund einer Dissertation nicht vergessen: sie ist und bleibt ein Bestandteil des Promotionsverfahrens. Also ist sie juristisch gesehen eine Prüfungsunterlage und Grundlage zur Führung eines akademischen Titels.
Diese Mehrfachfunktionen der Dissertation, einerseits Träger moderner wissenschaftlicher Ergebnisse, andererseits bibliothekarisches Objekt und nicht zu vergessen juristisch relevante Prüfungsunterlage, machen einen Umgang mit dieser Materie äußerst schwierig. Somit mussten Abstimmungen über den Metadatensatz mit den verschiedenen am Promotionsverfahren beteiligten Institutionen initiiert werden.
2. Metadaten in Dissonline 2.1 Datensatzentwicklung Kooperation mit wissenschaftlichen Fachgesellschaften
Da Dissertationen eine wissenschaftlich beachtliche Arbeit darstellen, ist es wichtig, dass jeder Fachwissenschaftler eine Möglichkeit besitzt, die für ihn interessanten Neuentwicklungen in seinem Fachgebiet suchen zu können. Daher verwenden viele Fachgesellschaften eigene Fachthesauri oder Klassifikationen. Zum Beispiel wird in der Mathematik die Mathematical Subject Classification (MSC)4 und in der Physik das Physics and Astronomy Classification Scheme (PACS)5 als Standard verwendet.
Neben der Erfragung eines Fachthesarus ist auch die allgemeine Unterstützung und Mitarbeit der Fachwissenschaftler von Bedeutung für den Erfolg unserer Bemühungen. Hierbei sollen insbesondere die Fakultätentage der verschiedenen Fächer angesprochen werden. Für den Bereich der Mathematik setzten wir uns für eine Kooperation mit der Konferenz mathematischer Fachbereiche (KMathF) ein.
Aufgrund dieser Kooperationen war es möglich, den Metadatensatz so zu gestalten, dass die Bedürfnisse der Fachgeschaften berücksichtigt werden konnten.
Kommunikation mit Prüfungsämtern
Die Metadaten einer Dissertation müssen aber aufgrund der schon erwähnten Doppelfunktion auch den Belangen des Prüfungsamtes genügen. Somit war eine Abstimmung der prüfungsrelevanten Daten mit den verschiedenen Fakultäten zu initiieren. Aus diesem Grund haben wir eine Sammlung mathematischer Promotionsordnungen bundesdeutscher Universitäten angelegt und ausgewertet. Damit aber eine allgemeine Gültigkeit dieser Ergebnisse garantiert werden kann, wurden andere Fachbereiche verschiedener Universitäten exemplarisch ausgewertet und in der Erhebung der dissertationsspezifischen Metadaten berücksichtigt.
Kommunikation mit Bibliotheken
Gemäß der Empfehlung von Prof. Lehmann6 legten wir einen Schwerpunkt unserer Abstimmungen in die Zusammenarbeit mit Der Deutschen Bibliothek (DDB)7. Aufgrund der gesetzlichen Archivierungspflicht der DDB waren die dortigen Mitarbeiter auch ihrerseits an einer engen Kooperation mit unserem Projekt interessiert. Die Diskussion über einen dissertationsspezifischen Metadatensatz sollte aber auf eine möglichst breite Basis gestellt werden. Daher konnte auch die Zusammenarbeit mit der SUB Göttingen8, die die Sondersammelbibliothek für den Bereich Mathematik darstellt und der Universitätsbibliothek Duisburg9 erreicht werden. Im Laufe der Diskussion wurde das Interesse von Seiten der Bibliotheken größer, so dass mehrere Universitätsbibliotheken, wie z.B. die Bibliothek der Humboldt-Universität Berlin, in die Absprachen integriert wurden.
Inhaltliche konzeptionelle Ebene
Aufgrund der unterschiedlichen Betrachtungsweisen von Dissertationen ergaben sich im Verlaufe dieser Koordination ungeahnte Schwierigkeiten. Daher kommt es in unserem Metadatensatz auch in einigen Punkten zu recht bizarren Konstruktionen, die nicht sofort als einsichtig erscheinen. Hier seien nur zwei dieser Punkte besonders erwähnt:
a) Daten
Wir unterscheiden vier Datumswerte, das Datum der Antragstellung zur Promotion und gleichzeitiger Abgabe der Gutachterexemplare, das Datum der rechtswirksamen Abgabe der Pflichtexemplare und das Datum der mündlichen Prüfung. Allen dreien kommt eine besondere Bedeutung im Promotionsverfahren zu und diese ist jeweils in den Promotionsordnungen fundiert. Hierbei geht es insbesondere um den Schutz der Eigentumsrechte an gewissen wissenschaftlichen Erkenntnissen, den Schutz vor Duplikaten und die Einhaltung der vorgeschriebenen Fristen für das Promotionsverfahren.
Die Hinzunahme eines vierten Datumswertes, des Datums der Veröffentlichung der Dissertation, wurde nach längerer Diskussion doch wieder gestrichen.
b) Titel
Es muss eine Unterscheidung zwischen dem Titel und dem Untertitel gemacht werden, dieses erscheint noch plausibel, desweiteren ist aber auch eine Unterscheidung zwischen den Originaltiteln und den übersetzten Titeln zu machen. Damit es nicht zu irgendwelchen Verwechslungen kommen kann, die gerade in Bereichen der Bibliothek zu Problemen führen können, sind vier verschiedene Titelfelder entstanden.
Interpretation in DC
Neben diesen inhaltlichen Abstimmungen war auch die Interpretation des DC zu koordinieren. In Zusammenarbeit mit dem Arbeitskreis Metadaten der IuK-Initiative der Fachgesellschaften10 und dem Projekt MetaLib11 konnte ein Vorschlag zur DC-Interpretation erarbeitet werden. Somit konnte ein dissertationsspezifischer Datensatz vorgestellt werden, dessen Kategorien weltweit verstanden werden können, da er in einer international normierten Codierung verfaßt worden ist.
Konzeption des Metadatensatzes
Aufgrund dieser umfangreichen Kommunikationen und Kooperationen konnte im Dezember 1998 ein dissertationsspezifischer Metadatensatz12 veröffentlicht werden, der den Ansprüchen der an einem Promotionsverfahren beteiligten Institutionen gerecht wird. In diesem Datensatz werden die Metadaten in die zwei Hauptkategorien unterteilt, die sich jeweils weiter untergliedern:
a) Dissertationsspezifische Daten
i) Bibliographische Daten, wie z.B. Promovend und Titel
ii) Fachspezifische Daten, wie z.B. Fachthesaurus und die inhaltliche Beschreibung
iii) Administrative Daten, wie z.B. Gutachter, Doktorvater und Promotionsdaten.
b) Formaldaten
i) reine Formaldaten, wie z.B. Sprache der Dissertation und Präsentationsformat
ii) Links zu den jeweiligen Klassifikationsschemata
Dieser Datensatz wurde Anfang 1999 in der damals üblichen HTML 4-Codierung geschrieben. Jedoch sind im Verlaufe der Entwicklungsarbeiten auch Probleme auf uns zugekommen, die zur damaligen Zeit nicht gelöst werden konnten. Hier sei nur das bekannte Beispiel von mehreren Autoren angesprochen.
Gerade für die Bibliotheken ist es von Bedeutung, die Autoren unterscheiden zu können. Jedoch ist es in HTML 4 nicht möglich, mehreren Autoreneinträgen auch die verschiedenen Emailadressen oder Geburtsdaten zuzuordnen. Dieses wäre nur über eine "private" Übereinkunft lösbar, dass z.B. die Reihenfolge der Einträge übereinstimmt und somit der erste Autor zum ersten Geburtsdatum gehört. Jedoch wird klar ersichtlich, dass diese Möglichkeit nicht sehr effizient ist und zu argen Verwirrungen führen kann. Dieses Problem hat mittlerweile jedoch eine Lösung erfahren. Hierbei handelt es sich um das Resource Description Framework (RDF)13. Diese Datenstruktur wird in einer XML-Codierung geschrieben und ermöglicht die Bildung von Containern, welches die oben beschriebene Problematik löst.
Aufgrund des schon angesprochenen DC7-Workshops haben wir uns entschlossen, den bisherigen Datensatz auch inhaltlich zu überarbeiten und an die neuesten Absprachen anzupassen. Desweiteren soll direkt eine Implementierung in das RDF-Schema vollzogen werden. Die Absprachen werden derzeit noch geführt, aber wir sind auf einem guten Wege und hoffen unsere Ergebnisse bald veröffentlichen zu können. Desweiteren wird der neue Datensatz nicht nur bundesdeutsche Gültigkeit haben, sondern es sind auch Gespräche mit Vertretern aus dem europäischen, asiatischen und nordamerikanischen Ausland initiiert worden. Daher soll es nach weiteren Diskussionen und Abstimmungen möglich sein, eine internationale Suche nach Dissertationen starten zu können (s. Teilprojekt Retrieval).
2.2 Tools Grundlagen
Nachdem der erste Punkt des Aufgabenpaketes, der dissertationsspezifische Metadatensatz, erfolgreich bearbeitet worden ist, konzentrierten sich die Arbeiten auf den weiteren Geschäftsgang der Promotion. Da die Entwicklung des Datensatzes im Hinblick auf das Retrieval erfolgte, muss den Suchsystemen auch die Möglichkeit gegeben werden, auf die Metadaten zugreifen zu können. Somit stellte sich also das Problem der Erstellung eines Datenfiles und der Verknüpfung von Dissertation und Metadaten.
Werkzeuge
In Gesprächen mit Promovenden stellte sich heraus, dass vielfach die Meinung herrscht, die Erstellung einer Dissertation sei fast einfacher als die richtige Umsetzung der Daten in das DC-Schema. Daher muss die Eingabe der Metadaten unkompliziert und leicht verständlich erfolgen. Desweiteren soll man bei den Daten unterscheiden, wem die Eingabe der korrekten Informationen am einfachsten fällt. Für manche Bibliothekare mögen die Eingaben gewisser Fachthesauri nur mit argen Problemen möglich sein, oder der Promovend kennt zur Zeit der Abgabe weder das zukünftige Präsentationsformat oder die URL seiner Dissertation. Aus diesen Beweggründen heraus konzipierten wir die zwei Eingabetools, den MyMetaMakerforThesis (MMMfT) und den Editor14.
Abbildung 1: Screenshot des MMMfT
Der MMMfT bildet das Grundtool, mit ihm werden die ersten Datenfiles erstellt. Es handelt sich um eine Eingabemaske, die äußerlich einem üblichen Fragebogen gleicht und somit den Promovenden keine Schwierigkeiten bereiten dürfte.
Dieses Tool wird an der jeweiligen Institution installiert, die sich für die elektronische Veröffentlichung der Dissertation verantwortlich zeichnet, im weiteren nur UB genannt. Die zur Installation benötigten Files stehen im Internet15 kostenlos zur Verfügung. Die Tools sind so aufgebaut, dass sie an die jeweiligen örtlichen Gegebenheiten ohne großartigen Aufwand angepasst werden können.
2.3 Installation
Die Installation der Tools (das Zweite, der Editor, wird im weiteren noch erläutert) erfolgt nach folgendem Plan.
a) Dekomprimieren Sie MMMfT-1.2.tar.gz durch:
gunzip MMMfT-1.2.tar.gz | tar -xvf
MMMfT-1.2 besteht aus folgenden Dateien:
Readme, MakeHelp-1.2.html, EditHelp-1.2.html, copyright.html, MMMfT-1.2.cgi, Edit-1.2.cgi, conf.pm, DC.pm, fachsp.pm, format.pm, lokal.pm, sprachen.pm und thesauri.pm
b) Erstellen Sie ein Verzeichnis "MMMfT" auf Ihrem WWW-Server und kopieren Sie die Dateien
(1) MakeHelp-1.2.html
(2) EditHelp-1.2.html
(3) copyright.html
dorthin.
c) Erstellen Sie ein Verzeichnis "MMMfT" in einem CGI-BIN Verzeichnis Ihres WWW-Servers und kopieren Sie die Dateien
(1) MMMfT-1.2.cgi
(2) Edit-1.2.cgi
(3) conf.pm
(4) DC.pm
(5) fachsp.pm
(6) format.pm
(7) lokal.pm
(8) sprachen.pm
(9) thesauri.pm
dorthin.
d) Der MMMfT läßt sich mit Hilfe der folgenden Dateien konfigurieren und den lokalen Gegebenheiten anpassen. Nach der Installation müssen die Dateien lokal.pm und fachsp.pm editiert werden! Die anderen Konfigurationsdateien können bei Bedarf editiert werden.
Im folgendem wird eine Übersicht über die Konfigurationsmöglichkeiten gegeben. Genauere Anweisungen zur Konfiguration sind in den Dateien selbst enthalten.
e) Sie können den MMMfT nun über MMMfT-1.2.cgi und den Editor über Edit-1.2.cgi aufrufen. (Evtl. müssen Sie in beiden CGI-Skripten den Pfad von perl ändern.)
2.4 Nutzung
Der MMMfT ist nun dem lokalen Bedarf entsprechend von der UB im Internet veröffentlicht worden und jeder Promovend kann auf diese Datenmaske via Internet oder direkt aus der UB zugreifen und seine Daten eingeben.
Nachdem die Daten erhoben worden sind, wandelt der MMMfT die Eingaben gemäß unserer Interpretationen in DC-Metatags um und man kann den so entstandenen Datenfile lokal auf seinem Rechner abspeichern. Die erfragten Daten sind auf den Kenntnisstand eines Promovenden abgestimmt, er wird also nicht mit Fragen behelligt, die er nicht beantworten kann.
Dieser lokale File wird nun mit dem Quellfile der Dissertation an die UB übergeben, die entsprechenden Modalitäten, d.h. per Diskette, ftp oder die Frage der Formate o.ä. sind von der UB zu bestimmen. Der Editor bildet, wie der Name schon vermuten läßt, ein Werkzeug zur Annotation der eingehenden Datenfiles. Öffnet man mit ihm einen Datenfile des MMMfT, so erscheint ein vergleichbares Eingabeformular und die existierenden Daten sind in den entsprechenden Feldern aufzufinden. Nun besteht die Möglichkeit, die Daten von Seiten der UB zu editieren und zu vervollständigen. Beendet man diesen Vorgang, so erstellt der Editor eine Frontpage, die einer Karteikarte früherer Bibliotheken entspricht. Im Vordergrund befinden sich die dissertationsspezifischen Daten wie der Name und das Abstract. Im Hintergrund (Header der Datei) befinden sich jedoch alle eingegebenen Metadaten im DC-Code. Somit ist es also möglich, allen an einem Ort publizierten Dissertationen ein einheitliches Bild zu verschaffen und den Suchmaschinen (siehe Teilprojekt Retrieval) kann ein Zugriff auf die Metadaten ermöglicht werden.

Abbildung 2: Modelworkflow mit den Metadatenwerkzeugen
Die Frage nach der Kontrolle der Metadaten hängt von der Organisationsstruktur der Universität ab. Es besteht die Möglichkeit, sich mittels eines Vertrages vom Promovenden bestätigen zu lassen, dass die vorliegenden Daten der Wahrheit entsprechen, oder man kann eine Kontrolle durch den Fachbereich oder den Promotionsausschuss einfügen (siehe Teilprojekt Retrieval).
Die nun vorgehaltene Frontpage besitzt alle über die Dissertation benötigten Informationen und wird im Internet veröffentlicht. Es ist nicht nötig, diese Seite und die Dissertation auf dem selben Server zu publizieren, wichtig sind nur die richtigen Verlinkungen von der Frontpage zur Dissertation.
Mit diesem Procedere ist die Dissertation nun also der Öffentlichkeit zugänglich und publiziert.
Nach der lokalen Archivierung der Daten und der Dissertation ist ein weiterer wichtiger Punkt die Anmeldung der Arbeit bei Der Deutschen Bibliothek (DDB). Die Deutsche Bibliothek ist seit Mitte März 1999 in der Lage, Metadaten zu Online-Dissertationen auf verschiedenen Transportwegen zu empfangen. Dies ist vor allem mit der Absicht geschehen, den Aufwand für die anmeldenden UB's zu verringern. Musste bislang ein Formular dort von Hand ausgefüllt werden, so sollen zukünftig bereits vorliegende Metadatenstrukturen nachgenutzt werden können. Dies gilt vor allem für die bruchlose Weiterleitung von Daten, die aus der Interaktion zwischen Promovend und der für die Annahme der Online-Dissertation zuständigen Stelle entstehen, wie z.B. beim MyMetaMaker for Theses.
Der Anstoß zur Aufnahme einer Online-Hochschulschrift in den DDB-Archiv-Server deposit.ddb.de erfolgt unabhängig von der für die Metadaten gewählten Transportvariante durch eine Email an die Abteilung Erwerbung der DDB.
Der Gang ist folgender:
Die UB schickt der DDB eine entsprechende Email. Adressat der Email ist: ep@dbf.ddb.de . Der Betreff der Email wird in der DDB zur Steuerung des Geschäftsganges und zur Identifikation des Absenders verwendet. Als Betreff ist deshalb erforderlich: ID-Nummer der abliefernden Stelle, "DC.Creator.PersonalName" der Hochschulschrift (Name, Vorname), DNB-Sachgruppe jeweils durch Schrägstrich voneinander getrennt, z.B.:
xxxnnnnn/Mayer, Harald/13
DDB nimmt an, dass der Absender der Email gleichzeitig der Ansprechpartner der abgebenden Stelle ist. Der Inhalt der Email besteht aus der URL eines HTML-Dokumentes, das Metadaten enthält, z.B.:
http://www.ub-uni.de/archserv/diss/0345.htm
Damit wird Systemen Rechnung getragen, die bereits im eigenen Umfeld HTML-Seiten als Metadatenträger eingerichtet haben. Sofern die in diesen Dokumenten eingelagerten Metadaten strukturell den an anderer Stelle genannten Konventionen entsprechen, werden sie von der DDB aus dem entfernt liegenden Dokument direkt extrahiert.
Bei der automatischen Bearbeitung des HTML-Dokumentes werden ausschliesslich Elementbezeichner der Art: <META NAME= ......> verarbeitet. Sonstiger Text wird ignoriert.
Die Elementbezeichner DDB.Contact.ID, DDB.NumberOfFiles und DDB.Contact sind auch in dieser Variante nicht obligatorisch.
Somit ist allen bürokratischen Feinheiten genüge getan worden und der Geschäftsgang abgeschlossen. Es lassen sich folgende Punkte kurz festhalten:
Folgende Punkte benötigt die UB für den obigen Geschäftsgang:
Aus der obigen Darstellungen wird auch deutlich, welche Daten wo liegen:
3. Suche mit Metadaten
Wie schon oben angesprochen, sind die Metadaten ein Werkzeug zur Unterstützung bzw. Ermöglichung einer qualifizierten Suche im Internet. Basierend auf dem von uns entwickelten Metadatensatz für Dissertationen haben wir eine Suchmaske für das Harvest-Suchsystem erstellt16. Damit die bei den einzelnen UB�s vorgehaltenen Dissertationen auch von dieser Suchmaschine gefunden werden können, benötigen wir die Adresse des Servers mit den Metadatenfiles, die ja im Netz publiziert sind. Somit kann eine deutschlandweite (und vielleicht auch bald internationale) Such nach Dissertationen durchgeführt werden. Man ist also nicht mehr gezwungen, die verschiedenen Standorte in Deutschland einzeln abzusuchen, sondern kann sich auf eine umfassende Suche beschränken. Die so ermöglichte Auffindbarkeit der elektronischen Dissertationen wird häufig als das wichtigste Ziel unserer Aktivitäten angesehen, aber leider können wir nur den Boden dafür bereiten und sind auf die Mithilfe der UB�s angewiesen. Nur wenn uns die URLs mitgeteil werden, können wir den Broker entsprechend konfigurieren. Es reicht nicht aus, die Daten an die DDB zu schicken und zu hoffen, der Broker findet sie dort, denn wie oben gesagt, ist die Datenbank der DDB nur über den hauseigenen OPAC zu durchsuchen und daher nicht für unsere Suchmaschine. Weitere technische Informationen werden im 2. Teil dieses Beitrages gegeben, der sich mit den Fragestellungen des Retrievals beschäftigt.
Eine Zusammenfassung der obigen Ergebnisse im Bereich des Geschäftsganges ist in der Abb. 3 S. 35 gegeben.
D. Teilprojekt Retrieval und rechtliche Aspekte
von Kerstin Zimmermann Der Konzeption und dem Aufbau eines weltweiten qualifizierten Suchinstrumentariums widmet sich das Teilprojekt Retrieval. Im letzten Teil des Artikels wird kurz auf die rechtlichen Aspekte der Online-Publikation von Dissertationen eingegangen. 1. Weltweites Retrieval nach und in Dissertationen
In Dissertationen werden neuste Forschungsergebnisse ausführlich beschrieben und dokumentiert. Daher ist ein schneller Zugriff auf diesen Dokumenttyp besonders wünschenswert. Doch bis dieser in der print-Version über Fernleihe bei der örtlichen Bibliothek erfolgen kann, vergeht viel Zeit.
Schneller und effektiver ist da ein Retrieval über die elektronischen Exemplare. Da diese in den Naturwissenschaften aber oftmals erst auf dem Fachbereichs-/ bzw. Institutsserver bereitgestellt werden oder in Teilen über preprint-Server einsehbar sind, ist eine Vernetzung dieser dezentralen Archive notwendig. Zentraler Baustein ist hier eine geeignete Suchmaschine.
1.1 Harvest: Funktionsweise
Die heutigen Suchmaschinen sind meist global, wenig spezialisiert. Hieraus resultieren eine Reihe grundlegender Probleme:
Viele "Treffer" sind gar keine, die Benutzer drohen in der Flut der Antworten zu ertrinken.
Viele Datenbankeinträge sind total veraltet, die Links funktionieren nicht mehr.
Die Suchmaschine unterstützt die User nur wenig oder gar nicht bei der Formulierung von Suchanfragen, da in die Suchmaschine kein Fachwissen einfließen konnte.
Besser ist in diesem Fall eine spezialisierte Maschine, die nur in bestimmten, vorher festgelegten Bereichen sucht � hier z.B. nach den Dokumenten bzw. deren Einträge auf einem WWW-Server, denn auch intern kann nach Dokumenten gesucht werden.
Eine Möglichkeit, dieses zu bewerkstelligen bietet die Harvest-Software. (ftp://ftp.tardis.ed.ac.uk/pub/develop/snapshots)
Mit ihren 2 Hauptbestandteilen, dem Gatherer und dem Broker, erlaubt sie eine Bündelung der fachspezifischen Informationen. Der Gatherer sammelt die Daten von den eingetragenen Adressen ein, extrahiert daraus die relevanten Informationen. Diese werden dann ins SOIF-Format (Summary Object Interchange Format) umgewandelt und gespeichert. Dieses Format erlaubt eine effektive Weiterverarbeitung und einen schnellen Datenaustauch bei einer Suchanfrage. Der Broker als Query-Manager übernimmt die eigentliche Indizierung der Daten. Er kann über ein WWW-Formular auf mehrere Gatherer und oder Broker zugreifen und die Suchanfrage gezielt bearbeiten. Standardmäßig liefert die HARVEST- Software den Glimpse mit. Es können aber auch andere Programme zur Indexierung benutzt werden.
1.2 Aufbau eines Harvest-Netzwerkes
Als Testbed wurde im Projekt PhysDis (http://elfikom.physik.uni-oldenburg.de/dissonline/PhysDis) benutzt:
Im fachspezifischen Suchdienst PhysDis sind alle physikalischen Institutionen aller europäischen Länder integriert, die Dissertationen nachweisen. Die Karte http://elfikom.physik.uni-oldenburg.de/dissonline/DisEUROPE.html zeigt diese 17 Nationen, mit unterschiedlicher Nachweisdichte. Es gibt eine �gutbestückte� zentrale Nord-Süd-Achse mit Schweden, Deutschland und der Schweiz mit vielen verteilten Dissertationsarchiven. Angrenzende Länder weisen meist noch einige Nachweisstellen auf. In Osteuropa schwindet es dagegen rapide.
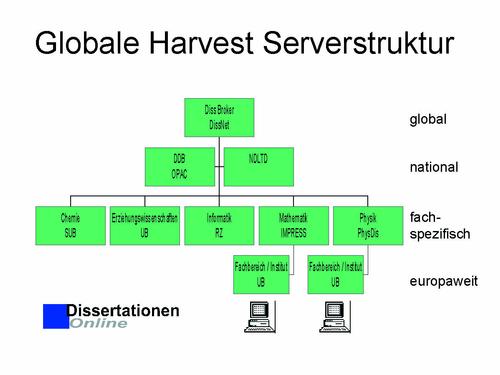
Abbilding 3: Globale Harvest Serverstruktur
Derzeit (Januar 2000) sind in PhysDis mehr als 2200 Dissertationen aus 17 Ländern verzeichnet. Diese verteilen sich auf 112 verschiedene Server und werden durch 306 Links vom Gatherer in Oldenburg indiziert. Die Laufzeit zur Erstellung der temporären Datenbank betrgt 2 Stunden und 40 Minuten.
In Deutschland weisen mittlerweile fast alle (54 von 63) Physikstandorte ihre
Dissertationen nach, sei es auf dem Fachbereichsserver oder durch die Universittsbibliothek.
Fächerübergreifend nimmt bis jetzt über die Hälfte aller Universitätsbibliotheken digitale Dissertationen an. Eine vollständige Liste ist unter http://elfikom.physik.uni-oldenburg.de/dissonline/unibib.html zu finden.
Der Suchmaschine PhysDis liegt ein sehr heterogenes Angebot zu Dissertationen zugrunde. Je nach lokalem System und Aufbereitung der Daten lassen sich 4 unterschiedliche Kategorien der Qualität ausmachen:
a) Liste mit Einträgen (Name, Titel, Datum)
b) zusätzlich mit Abstract
c) Volltexte unkommentiert
d) Metadaten und Volltexte
Anzustreben ist natürlich Möglichkeit d) mit dem einheitlichen Metadatensatz nach dem DC-Standard und einem Volltext im .ps- oder .pdf-Format zur Präsentation. Hier kann dann in den einzelnen Feldern der Metadaten eindeutig recherchiert werden.
Geplant ist später nach Dissertationen aller Fächer bundesweit bzw. in einem Fachgebiet weltweit über eine einheitliche Suchmaske recherchieren zu können. Dazu ist eine �intelligente� Vernetzung der Server dringend erforderlich. Die Abb. 4 zeigt einen Entwurf einer solchen Struktur:
Ausgehend von einer Eingabemake kann global gesucht werden: Einmal über die Nationalbibliotheken wie die DDB, Portugal, Österreich,etc oder nationale Projektarchive wie NDLTD17. Hier wird gerade im Rahmen des Projektes eine gemeinsame Schnittstelle entworfen. Desweiteren ist eine fachspezifische Einschränkung möglich. Dazu sind schon Gatherer in der Mathematik und in der Physik installiert, die wiederum einen europaweiten Einzugsbereich haben.
Geplante Netzwerkstruktur für einen Dissertations-Suchdienst
Der Broker sollte die Aufgabe erfüllen, die Universitätsbibliotheken (UBs) und Die Deutsche Bibliothek (DDB) absuchen zu können und auch bekannte Links im Ausland mit einzubeziehen. Er kann sowohl der jetzigen Lage einer verteilten imhomogenen Speicherung wie auch einem eventuell späteren Zentralarchiv gerecht werden. Der schrittweisen Angleichung der Dissertationenarchive kann so immer Folge geleistet werden ohne abrupte Umstellung auf ein bestimmtes Softwareprogramm.
Da ein weiterer Ausbau der Retrievalmöglichkeiten von HARVEST im Rahmen des CARMEN18-Projektes als Sonderfördermaßnahme in Global Info erfolgen wird, ist hier immer auch ein aktueller Stand der Technik berücksichtigt.
1.3 Kooperationen mit anderen Systemen
Da Harvest Index-file im SOIF-Format erstellt, mit dem der Abgleich der Daten erfolgt, wenn eine Suchanfrage gestellt wird, ist ein Austausch mit anderen, lokalen Datenbanken auch plattformübergreifend möglich. Als �public domain� Software ist der Quellcode offen zugänglich und kann so an alle Erfodernisse angepasst werden. Hinzu kommt die Kostenersparnis durch das freie Downloaden.
So soll auch in Zukunft die NDLTD-Suchmaschine (Merian) angebunden werden.
2. Rechtliche Aspekte bei elektronischen Dissertationen
Rechtfragen bezüglich elektronischer Datenquellen im internationalen Kontext werden in der Workgroup DC.Rights diskutiert. Hier legt das TP 2 einen besonderen Augenmerk auf die Dissertationen auch mit Multimediaelementen und deren Metadaten. Es zeigt sich, dass für eine allgemeine Verbindlichkeit neue Regelungen getroffen werden müssen wie �(un)restricted access / use�, die mit anglo-amerikanischem, australischem und möglicherweise übergreifendem EU-Recht in Einklang stehen. Zur weiteren Spezifizierung kann dann z.B. auf das Copyright in den einzelnen Ländern verwiesen werden.
2.1 Promotionsverfahren Grundlegendes
Die Promotionsordnungen der Fachbereiche/Fakultäten fordern eine Veröffentlichung der Dissertation. Damit soll die Authentizität, Einsehbarkeit, Nachprüfbarkeit und Zitierfähigkeit gewährleistet werden. Dieses kann mittlerweile an vielen Universitätsstandorten und Bibliotheken elektronisch geschehen.
Bisher hat die Erstgutachterin die endgültige Publikationsform eingesehen und das �Imprimatur� erteilt, der Fachbereich ein gekennzeichnetes, benotetes �Original� für eine begrenzte Zeit einbehalten, sowie die Promovendin eine Anzahl von gedruckten Pflichtexemplaren an die Bibliothek abgeliefert. Die Bibliothek hat dann gedruckte Exemplare mit einer Reihe anderer Bibliotheken getauscht und ein Exemplar an die DDB zur Archivierung weitergeleitet.

Abbildung 4: Online Publikation von Dissertationen
Die Promovendin besitzt aber alle sich aus dem Urheberrecht ergebenden Rechte an ihrer Arbeit, von denen die wichtigsten im folgenden kurz genannt sind: Das Vervielfältigungsrecht (� 16 UrhG) mit dem Recht zur Verbreitung (� 17 UrhG), Ausstellungs- sowie Vortrags- und Senderecht, ebenso das Nutzungsrecht (� 17 UrhG). Das Werk ist bis 70 Jahre nach dem Tod der Autorin urheberrechtlich geschützt. Dies ist unabhängig davon, ob die Arbeit in gedruckter, elektronischer oder anderer Form vorliegt.
Geschäftsgang am Fachbereich
In den Geschäftsgang am Fachbereich sind verschiedene juristische und natürliche Personen mit ihren Rechten und Pflichten involviert, daher oben auf Seite 39 nochmals eine kurze Übersicht. Am Ende steht nach wie vor die Aushändigung der Promotionsurkunde als rechtliches Dokument
In der Physik ist angedacht, den gesamten Geschätsgang elektronisch abzuwickeln, dies schließt auch die Einsichtnahme und die Gutachten mit ein. Dabei ist allerdings das Verwenden von elektronisches Signaturen dringend erforderlich, um einen Rechtsbeweis erbringen zu können.
2.2 Online Publikation
Auch bei einer elektronischen Dissertation gelten die gleichen Anforderungen wie an eine gedruckte Dissertation, hier werden jetzt auch die Metadaten zusätzlich elektronisch erfasst. Das Meldeverfahren an die DDB kann per email erfolgen und es wird weiterhin Sondersammelgebiete an verschieden Standorten geben (Spiegelserver).
Die Recherche über die Metadaten und die Online-Versionen ist frei verfügbar.
Zu einer Dissertation gehört ein Lebenslauf. Dieser wird der bei einer Online-Publikation ebenfalls elektronisch gespeichert. Hier greift das Datenschutzgesetz. Für die Speicherung und Verbreitung dieser personenbezogenen Daten muss daher eine Einverständniserklärung der betreffenden Person vorliegen. Die gilt sowohl für den Fachbereich als auch für die Bibliotheken, an die diese Daten weitergereicht werden.
2.3 Nationale Datenbanken
Die Speicherung von Doktorarbeiten auf Universitätsservern, insbesondere des Lebenslaufes kann rechtlich als Speicherung in einer Datenbank angesehen werden. Daher ist die Einverständniserklärung des Autor für eine derartige Publikation unbedingt erforderlich.
In Anlehnung an das Oldenburger Modell und um eine vergleichbarer Rechtsverbindlichkeit zu schaffen sind die erarbeiteten Musterverträge19 für die einzelnen Beteiligten (Kandidatin-Fachbereich, Kandidatin-Bibliothek, Fachbereich-Bibliothek) im Netz abrufbar.
Hierin werden Authentizität (elektronisches Exemplar identisch mit gedruckter Prüfungsversion), Überprüfung und Freigabe der Daten sowie Einverständniserklärung im Sinne des Datenschutzgesetzes festgelegt.
Wird von der Autorin eine (zusätzliche) Verlagsveröffentlichung angestrebt, so ist bei Abschluß des Vertrages auf die eventuell bereits vorhandene elektronische Version der Arbeit bei der Universitätsbibliothek oder dem Fachbereichs-Server hinzuweisen, und notfalls die entsprechende Klausel auf alleiniges Verbreitungsrecht (soweit vorhanden) zu streichen bzw. zu durch Verweis auf die zweckmässig zu Beginn der Promotion mit dem FB abgeschlossenen Vereinbarung zu modifizieren.
| Im Text verwendete Abkürzungen | |
| UB | Universitätsbibliothek |
| DNB | Deutsche Nationalbibliographie |
| DDB | Die Deutsche Bibliothek |
| URL | Uniform Resource Locator |
| HTML | Hypertext Markup Language |
| XML | Extensible Markup Language |
| OPAC | Online Public Access Catalogue |
1. Beispielsweise eine allgemeine Suche nach dem Textverarbeitungsprogramm LaTeX, von 16 Ergebnissen mit Yahoo, beschäftigen sich nur zwei mit dem Programm.
2. http://www.oclc.org:5046/research/dublincore/
3. Die Qualifier-Ebene wurde auf DC7 im Oktober 1999 an der DDB in Frankfurt/Main verabschiedet, vgl. http://www.ddb.de/partner/dc7conference/index.htm
4. http://www.zblmath.fiz-karlsruhe.de/class/MSC91/index.html
5. http://publish.aps.org/PACS/pacsgen.html
6. Während der Projektlaufzeit noch Generaldirektor Der Deutschen Bibliothek (DDB)
7. Frau Schwens (schwens@dbf.ddb.de) Frau Hengel-Dittrich (hengel@dbf.ddb.de) Herr Weiß (weissb@dbf.ddb.de)
8. Herr Becker (Becker@mail.sub.uni-goettingen.de)
9. Frau Heine (p-he@duisburg.uni-duisburg.de)
10. http://www.mathematik.uni-osnabrueck.de/ak-technik/IuKKwF.html
11. http://www.ddb.de/partner/metalib.htm
12. http://www.ub.uni-duisburg.de/dissonline/metatags.html
13. http://www.w3.org/TR/PR-rdf-syntax/
14. http://elib.Uni-Osnabrueck.DE/MMMfT/
15. http://elib.Uni-Osnabrueck.DE/MMMfT
16. http://elib.uni-osnabrueck.de/Harvest/brokers/DissOnline/
18. http://www.globel-info.org/sfm/carmen.htm
19. http://elfikom.physik.uni-oldenburg.de/dissonline/vertrag.html
Thorsten Bahne, Diplom-Mathematiker, ist seit Mai 1998 Mitarbeiter bei Prof. Törner im Teilprojekt Metadaten am Fachbereich Mathematik der Gerhard-Mercator Universität Duisburg.
E-Mail: Bahne@math.uni-duisburg.de
![[Kerstin Zimmermann]](../../images2/zimmer.jpg)
Kerstin Zimmermann, Diplom-Physikerin, ist seit März 1998 Mitarbeiterin bei Prof. Hilf am Fachbereich Physik der Carl-von-Ossietzky Universität Oldenburg.
E-Mail: kerstin@merlin.physik.uni-oldenburg.de