
Abb. 1: Visualisierung eines Autoren-Netzes3
von Dieter Schwartz
1. Einleitung
2. Allgemeine und spezielle Anwendungsbeispiele
3. Visualisierungssysteme
4. Visualisierung von Daten und Generierung von Informationsräumen
1. Einleitung
|
Abb. 1: Visualisierung eines Autoren-Netzes3 |
Datenmengen können nach unterschiedlichen Gesichtspunkten aufbereitet und damit unterschiedliche Beziehungen aufgezeigt werden. So lassen sich beispielsweise Inhalte von Zeitschriftenartikeln auf der Grundlage von Ähnlichkeiten zwischen Keywords oder Klassifikationselementen oder über semantische Beziehungen strukturieren; insbesondere können charakteristische Dokumentbeziehungen über eine Betrachtung der Autoren offengelegt werden (Vgl. Abb. 1).
2. Allgemeine und spezielle Anwendungsbeispiele
Entscheidungsträger aus Wirtschaft, Politik und Wissenschaft erhoffen sich aussagekräftige Antworten bei ihrer Suche in umfangreichen Datenbeständen. Unterschiedlichste Fragestellungen können dabei bearbeitet werden. Unternehmen interessiert beispielsweise ein umfassendes Bild konkurrierender Forschungs- und Entwicklungsaktivitäten; im Rahmen ihrer strategischen Ausrichtung suchen sie nach möglichen Partner-Unternehmen, die die im eigenen Spektrum fehlenden Technologiefelder besetzt haben. Mit Hilfe geeigneter Werkzeuge kann eine Analyse des Wissenschafts- und Technologiemanagements von Unternehmen erfolgen.4 So umfasst beispielsweise die strategische Patentanalyse eine technologische Konkurrenzanalyse, ein F&E-Management, eine externe Technologiebeschaffung oder Marktüberwachung.5 Demgegenüber ist für Finanzunternehmen wichtig, den "Weg des Geldes" nachzuvollziehen und für ihre Kunden transparent darzustellen. So bietet eine internationale Investment-Bank entsprechend aufbereitete Informationen aus Datenbanken mit Visualisierungskomponenten an.6
Neben betrieblichen Entscheidungsträgern will auch die Wissenschaftspolitik über aktuelle Entwicklungen informiert werden. In diesem Zusammenhang sind u.a. herausragende Strukturelemente einer zukunftsweisenden Wissenschaft von Interesse. Im Rahmen von Systemevaluationen wird beispielsweise nach gemeinsam geförderten Forschungsrichtungen gesucht. Wesentliche Grundlage für ein derartiges Technologie- und Wissenschaftsmapping bildet i.a. der Science Citation Index des Institute for Scientific Information.7 Tätigkeits- und Aufgabenbereiche von Forschungseinrichtungen oder Unternehmen werden dabei auf der Grundlagen bibliographischer Daten ermittelt.
Eine Visualisierung bietet sich für Datenstrukturen an, die einer zeitlichen Veränderungen unterliegen. Dies können Datenströme innerhalb des Internets sein. Betrachtungsgrößen sind beispielsweise das Wachstum des Internets, die globale Verteilungsdichte der Hosts oder das veränderte Informationsaufkommen im Internet.8 Auf der Grundlage des Datenaustauschs innerhalb von Newsgroups wurde ein Visualisierungsmodell erprobt, mit dessen Hilfe - im Unterschied zu statischen Datensammlungen - die Kohärenz von Datenströmen dargestellt wird.9
3. Visualisierungssysteme
3.1 Unterschiedliche Werkzeuge und Features
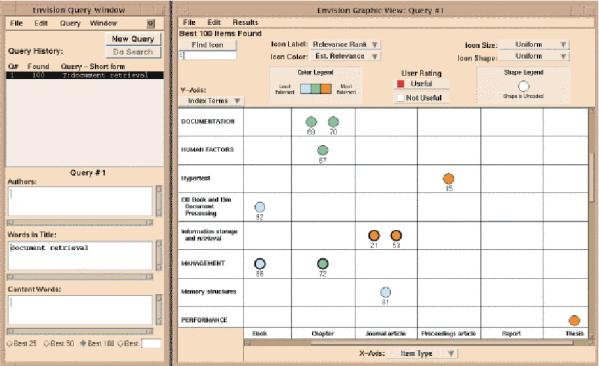
Abb. 2: Darstellung von Recherche-Ergebnissen am Beispiel Envision3
Envision war eines der ersten Instrumente, das für den Bereich Computer Science eingesetzt wurde.10 Diese "digitale Bibliothek" ermöglicht ein Volltext-Retrieval, wobei die Suchergebnisse in einer Matrix ausgegeben werden. Über die in dieser Matrix angeordneten Icons kann die Suche verfeinert werden. Die Eigenschaften eines Dokuments werden über Farben angezeigt; so spiegeln beispielsweise weiße gegenüber roten Elementen eine geringere Relevanz der Inhalte wider.11
Lyberworld ermöglicht die Navigation in Informationsräumen und bietet eine interaktive Benutzerschnittstelle. Das System stellt Datenmengen dreidimensional über Planetensysteme dar. Aus dem content space, als dem gesamten Informationsraum, wird der context space generiert, also der Informationsraum, in dem Ergebnisse präsentiert werden. Das System greift den Gestaltungs- und Interaktionsgedanken der virtual reality auf.
Mit SPIRE wird ein Werkzeug zur Verfügung gestellt, das ebenfalls die Dokumente in einer Galaxie anordnet und außerdem ein Themenfeld anbietet. In der Galaxie werden Dokumente gruppiert - vergleichbar einem Sternen-Cluster im Nachthimmel; die Entfernung zwischen den Dokumenten liefert eine Aussage über die Ähnlichkeit oder inhaltliche Verwandtschaft der Dokumente. In dem Themenfeld werden die verschiedenen Dokumente als Relief einer Landschaft - vergleichbar einer topographischen Landkarte - dargestellt. Auch hier werden ähnliche Dokumente gruppiert; Erhebungen innerhalb der Landschaft geben Auskunft über die relative Häufigkeit eines Themas.
Das Visualisierungstool VxInsight ordnet ebenfalls Dokumente innerhalb einer Landschaft an, wobei Beschreibungsdaten und Verknüpfungen zwischen einzelnen Elementen dargestellt werden. Es können vergrößerte Ausschnitte gezeigt werden und Bewegungen innerhalb der Landschaft erfolgen. Ein zeitlicher Verlauf der "Dokumenten-Entwicklung" wird nachgezeichnet, indem Verbindungen zwischen neuen und alten Dokumenten dargestellt werden.12
3.2 Bestandteile eines Systems
Obgleich eine breite Palette unterschiedlicher Werkzeuge zur Visualisierung von Daten existiert13, sind diese durch vergleichbare Funktionselemente (Module) gekennzeichnet. Grundlegende Bestandteile dieser Systeme sind Schnittstellen, über die die Interaktionen zwischen System und Benutzer ablaufen, und Kontrollsysteme, die die internen Abläufe überwachen und Berechnungen durchführen. Weiterhin erforderlich sind Filter, mit deren Hilfe u.a. eine Reduktion des Datenvolumens und eine Strukturierung der Inhalte erfolgt (z.B. Ausschluss redundanter Dokumente). Ein weiteres Modul ist für die Clusterung verantwortlich. Auf der Grundlage der gefilterten und geclusterten Daten erfolgt die Darstellung des Informationsraumes, das sogenannte Mapping. Dieser Informationsraum ist ein internes Datenmodell, das mit Hilfe des Moduls Renderer auf den Bildschirm umgesetzt wird.14
4. Visualisierung von Daten und Generierung von Informationsräumen
4.1 Von den Eigenschaften zum Informationsraum
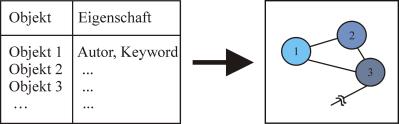
|
|
Abb. 3: Von den Eigenschaften zu den Beziehungen16 |
Inhaltliche Beziehungen zwischen Dokumenten lassen sich über Kräftegleichgewichte veranschaulichen: ähnliche oder inhaltlich verwandte Dokumente haben hohe Anziehungskräfte und liegen damit dicht aneinander; inhaltlich fremde Dokumente stoßen sich ab und sind deshalb weiter von einander entfernt. Über ein berechnetes Kräftegleichgewicht zwischen den Objekten entsteht auf diese Weise ein Netzsystem. Die unterschiedlichen Dokumente ordnen sich dabei in eine Landschaft ein: die Höhe der dadurch entstehenden Berge ist proportional zur Anzahl der dort angesiedelten Dokumente, was in der nachfolgenden Graphik durch entsprechende Farbwerte wiedergegeben wird (Vgl. Abb. 4). Die einzelnen Dokumente sind farblich unterschiedlich (blau, grau) markiert, die Verbindungen zwischen den Elementen sind gelb dargestellt.
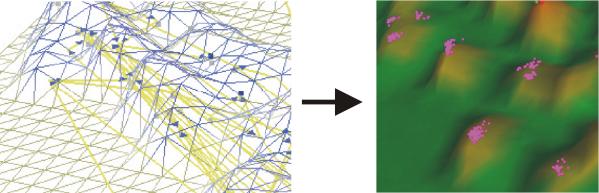
|
|
Abb. 4: Von den Beziehungen zum Informationsraum17 |
4.2 Ein Informationsraum am Beispiel Autorennetz
Eine Verwandtschaft zwischen Dokumenten kann beispielsweise über die Beziehungen zwischen den Autoren aufgezeigt werden. Eine Suchanfrage muss dabei zunächst auf den Dokumentenbestand abgebildet werden. Auf der Basis von mathematischen Modellen wird aus den Dokumenten eine Text-Matrix erzeugt, auf die die Suchanfrage abgebildet und damit eine Ähnlichkeitsmatrix zwischen Dokumenten generiert wird. Auf diese Weise können Dokumente gefunden werden, die aufgrund der Suchanfrage relevant sind, in denen aber die Wörter der Suchanfrage nicht erscheinen. Zwischen den Dokumenten bestehen unterschiedlich zu gewichtende Beziehungen. Über Gewichtungsverfahren können die relevanten Verbindungen herausgearbeitet und errechnet werden.18 Dies Verfahren zur Skalierung von Verbindungen führt dazu, dass die Anzahl der Verknüpfungen auf ein überschaubares Maß reduziert wird und damit weniger Verästelungen in der Graphik entstehen.
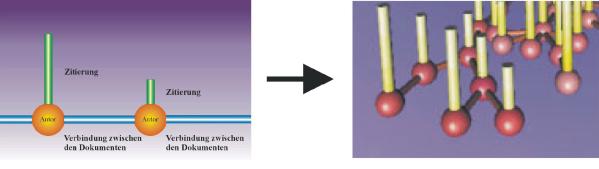
Abb. 5: Visualisierung von Eigenschaften und Beziehungen
Eine Darstellung von Recherche-Ergebnissen in virtuellen Räumen kann mit Hilfe unterschiedlicher Werkzeuge erfolgen (vgl. Kap. 3.1). Ein virtueller Raum kann beispielsweise auf der Basis von geometrischen Grundelementen (Kugel, Zylinder) sowie entsprechenden Farbwerten generiert werden. Dabei werden Dokumente als Kugeln und die Beziehung zwischen den Dokumenten durch verbindende Zylinder dargestellt. Der Umfang eines Dokuments wird durch die Größe des Radius und ein identisches Publikationsjahr durch gleiche Farbwerte wiedergegeben. Die Stärke der inhaltlichen Beziehung (semantische Verwandtschaft) spiegelt sich in der Dicke des verbindenden Zylinders, der Grad der inhaltlichen Beziehung in der Länge des Zylinders wider. Die Relevanz der Suchanfrage bezogen auf ein einzelnes Dokument wird über die Höhe und Farbwerte des Zylinders angedeutet, der auf den Dokumenten bzw. Kugeln angeordnet ist.
Auf diese Weise lassen sich Beziehungen zwischen unterschiedlichen Autoren und Zusammenhänge zwischen (aktuell und in der Vergangenheit) benutzten Quellen darstellen (Vgl. Abb. 5).19 Des weiteren kann die zeitliche Änderung von Zusammenhängen zwischen Dokumenten nachgezeichnet werden, also ein Wachsen von Verästelungen oder ein Entstehen von neuen Hauptzweigen. Eine räumliche Anordnung spiegelt eine Kombination von Dokumenten wider. Eine Visualisierung liefert also einen intuitiven Zugang zu Inhalten einer digitalen Bibliothek - sei es über ein Autorennetz, sei es über inhaltliche Strukturen.20
5. Ausblick
Unterschiedliche Anwendungsbeispiele für die Aufbereitung von Rechercheergebnissen und deren Visualisierung sind in der Literatur zu finden. Visualisierungstechniken haben dabei in unterschiedlicher Form Einzug in die Praxis gefunden. Der Datenbank-Lieferant LexisNexis präsentiert seine Produktübersicht beispielsweise in Form eines Hyperbolic Tree; diese Interactive View Map ist im WWW zu finden.21 Ein weiteres Beispiel liefert der Digital Library Visualizer, der über die Navigation in einer Bilddatenbank ein verbessertes Verständnis von großen Dokumentmengen in einer digitalen Bibliothek ermöglicht.22
Trotz zahlreicher Forschungs- und Entwicklungsarbeiten zum Einsatz von Visualisierungstechniken und dem Aufbau von virtuellen Welten bleiben die Arbeiten auf z.T. eng begrenzte Datensammlungen beschränkt. Es scheint sich jedoch abzuzeichnen, dass Visualisierungstools zu alltäglichen Bestandteilen des Internets und des sich daraus entwickelnden Interspace werden.23 Umfangreiche Forschungs- und Entwicklungsarbeiten sind erforderlich, um diese Techniken in der realen Umgebung einer digitalen Bibliothek zu testen und dabei insbesondere das spezifische Nutzerverhalten einzubeziehen.24
Zum Autor
Dipl-Ing. Dieter Schwartz
Hochschulbibliothek
Fachhochschule Münster
Corrensstraße 25
D-48149 Münster
E-Mail: dieter.schwartz@fh-muenster.de
Anmerkungen
1. Nach einer Studie der University of California in Berkely umfasst das Gesamtvolumen aller derzeit verfügbaren Informationen 12 Exabyt. Das entspricht dem Inhalt von 120.000.000.000.000 Büchern.
<www.sims.berkeley.edu/how-much-info>
2. Durch die Einrichtung von Metadaten-Schichten im Semantic Web sollen Software-Agenten in die Lage versetzt werden, die Semantik - i.S.e. Bedeutung von Daten - auf der Grundlage von computergestützten Regeln abzuleiten und damit Ähnlichkeiten und Verwandtschaften zwischen Dokumenten zu generieren.
3. Vgl. Börner, Katy; Chen, Chaomei; Boyack, Kevin: Visualizing Knowledge Domains. In: Annual Review of Information Science & Technology.
<www.asis.org/Publications/ARIST/Vol37/BornerFigures.html>
4. Um die effiziente Informationsversorgung innerhalb eines Unternehmens zu bewältigen, ist u.a. intelligente Wissensorganisation, Monitoring und Wissenscontrolling erforderlich. Vgl. Gerick, Thomas: Zur Nachfrageorientierte Informationsversorgung als Basis eines effizienten Wissensmanagements.
5. Vgl. Benoit, G.: Data Discretization for Novel Relationship Discovery in Information Retrieval. In: Journal of the American Society for Information Science. 53 (2002) 9, S. 736-746.
6. Finanzbeziehungen für den Bereich Technologie, Medien und Telekommunikation werden aufgezeigt. Weitere Beispiele auf den Seiten "In the News".
<www.arcassociates.com/news/fr_innews.html> und
Ameritech Principal Investments. In: Telecommunications, May 1999, S. 11.
<www.arcassociates.com/images/ameritec_invest_big.jpg>
7. Vgl. u.a. : Cawkell, Tony: Visualizing Citation Connections. In: The Web of Knowledge. Hrsg. von Blaise Cronon. 2000. S. 177-194. - Small, Henry: Charting pathways through Science: exploring Garfield's Vision of a Unified Index to Science. In: The Web of Knowledge. Hrsg. von Blaise Cronon. 2000. S. 449-473. - Boyack, K. W.; Wylie, B. N.; Davidson, G. S.: Domain visualization using VxInsight for science and technology management. In: Journal of the American Society for Information Science and Technology. 53 (2002) 9, S. 764-774. - Ein Mapping kann auf der Grundlage einer Patentanalyse mit Hilfe von graphischen Verfahren erfolgen. Insbesondere für diesen Bereich werden Vorteile eines graphischen Verfahren beschrieben in: Boyack, K.W.; Wylie, B.N.; Davidson, G.S.; Johnson, D.K.: Analysis of patent databases using VxInsight. Paradigms in Information Visualization and Manipulation 2000.
<http://citeseer.nj.nec.com/581895.html>
8. Eine detaillierte Zusammenstellung findet sich unter: <www.mids.org/index.html>
9. Vgl. Kaban, Ata; Girolami, Mark: A Dynamic Probabilistic Model to Visualise Topic Evolution in Text Streams. In: JIIS 18 (2002) 2-3, S. 107-125.
10. Zum Projekt vgl. PROJECT ENVISION - FINAL REPORT.
<http://ei.cs.vt.edu/papers/ENVreport/final.html> - Vgl. a. Fox, E. A.: Digital Libraries. In: IEEE Computer, 26 (November 1993) 11, S. 79-81.
11. Vgl. Envision Digital Library Project (1991-95)
<www.dlib.vt.edu/projects/Envision/>
12. Eine Beschreibung dieses kommerziellen Produktes des Unternehmens findet sich unter: <www.cs.sandia.gov/projects/VxInsight.html>
13. Neben den hier aufgeführten sind weitere Werkzeuge vorhanden, die in der Praxis bereits eingesetzt werden oder noch in der Entwicklung sind. Weitere Instrumente sind Sentinel oder SCI-Map. Vgl. Fox, Kevin L.; Frieder, Ophir; Knepper, Margaret M.; Snowberg, Eric J.: SENTINEL: A Multiple Engine Information Retrieval and Visualization System. In: Journal of the American Society of Information Science
<http://citeseer.nj.nec.com/fox99sentinel.html>
Vgl. a. Small, H.: A SCI-MAP case study: Building a map of AIDS research. In: Scientometrics. 30 (1994) 1, S. 229-241.
14. Der Renderer generiert also aus einem mehr-dimensionalen Modell eine zwei-dimensionale Bildschirmdarstellung. Mit Hilfe entsprechender Algorithmen werden Graphen produziert, die wie Projektionen von 3-D-Graphiken aussehen. Vgl. Bruß, I.; Frick, A.: Fast Interactive 3-D-Graph Visualization. In: Proceedings der Graph Drawing'95, Band 1027 der Lecture Notes in Computer Science. Hrsg. von F. Brandenburg, 1996. S. 99-110.
<http://citeseer.nj.nec.com/bruss96fast.html>
15. Ein Daten-Modell, mit dessen Hilfe große Informationsräume gemanagt werden können, wird beispielsweise vorgestellt in: Benoit, G.: Data Discretization for Novel Relationship Discovery in Information Retrieval. In: Journal of the American Society for Information Science 53 (2002) 9, S. 736-746.
16. Vgl. Boyack K. W.: Informations Visualizion, Human-Computer Interaction, and Cognitive Psychology: Domain Visualization.
<http://citeseer.nj.nec.com/boyack01information.html>
17. Vgl. Boyack, K. W., Wylie, B. N., Davidson, G. S.: Domain visualization using VxInsight for science and technology management. In: Journal of the American Society for Information Science and Technology. 53 (2002) 9, S. 764-774.
18. Zum Konzept des Pathfinder Network Scaling vgl. Chen, C.: Visualising semantic spaces and author co-citation networks in digital libraries. In: Information Processing & Management. 35 (1999) 3, S. 401-420.
19. Vgl. Chen, C.; Kuljis, J.: The rising landscape: A visual exploration of superstring revolutions in physics. In: JASIST 54 (2003) 5, S. 435-446.
20. Die Beziehungen zwischen Autoren und Co-Autoren auf der Grundlage einer Analyse der Zitierung werden vorgestellt in: Chen, C.: Visualising semantic spaces and author co-citation networks. In: Digital Libraries Information Processing & Management 35 (1999) 3, S. 401-420.
21. Interactive Map View.
<www.lexisnexis.com/startree/interactiveview.asp>
22. Datengrundlage ist eine Bild-Datenbank des Departement of the History of Arts der Indiana University. Vgl. Börner, Katy; Dillon, Andrew; Dolinsky; Margaret: LV is Digital Library Visualizer (2000).
<http://citeseer.nj.nec.com/559314.html>
23. Vgl. Schatz, B.: The Interspace: Concept Navigation across Distributed Communities. In: IEEE Computer. 35 (Jan 2002) 1, S. 54-62.
24. Zum Nutzerverhalten vgl. Allen, Maryellen Mott: The Hype Over Hyperbolic Browsers. In: online 26 (MAY/JUNE 2002) 3.